In the last post in the Explanck series, we built a tokenizer. After creating a tokenizer, the next step is to build a parser, but before we do that, we need to understand some theory behind what a parser generates: abstract syntax trees.
In this post, we will equip ourselves with this theoretical foundation.
Abstract Syntax Trees 🔗
An abstract syntax tree is a tree representation of code. For example, consider an expression like 6 / 2 * 4. We can
represent it as the following tree:
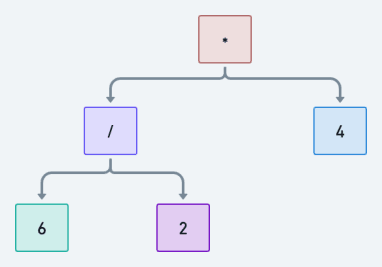
Leetcode faithfuls will have caught on to the fact that we can
use post-order traversal to generate our value. First, we
evaluate 6 / 2 to get 3, and then we evaluate 3 * 4 to get 12. Smooth.
However, we can also represent the expression as this tree:
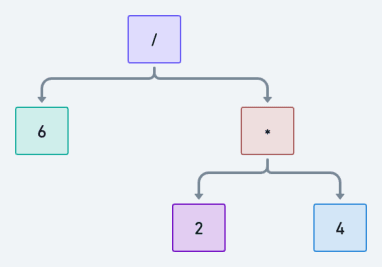
And if we traverse it in a post-order fashion, we evaluate 2 * 4 first to get 8. Then we evaluate 6 / 8 to
get 0.75.
One expression can generate at least two ASTs if there are no rules. And you see that the two ASTs generate two different values, which is problematic. Remember our income statement example from the previous post?
The rules we must define to prevent this from happening are called the [formal] grammar of the language. Sometimes, even when there are rules, generating more than one AST may still be possible. A grammar with rules that allow that is called an ambiguous grammar. In explanck, we will avoid them like the plague.
So, let’s talk about grammars.
Grammars 🔗
A formal grammar is a set of rules that defines what is valid within a language. In particular, we care about a type of formal grammar called context-free grammar (CFG). Each rule in a CFG is of the form head := body. head is the rule’s name, and body describes the symbol(s) the rule generates.
Symbols come in two forms: terminals and non-terminals. If a symbol within a body refers to another rule’s head (or name), then that symbol is a non-terminal - this means that the symbol can be converted to other symbols using a rule. A symbol is a terminal if no rule exists that can convert it to another symbol.
We all know about grammar from human languages, like English, so let’s use that to understand our context.
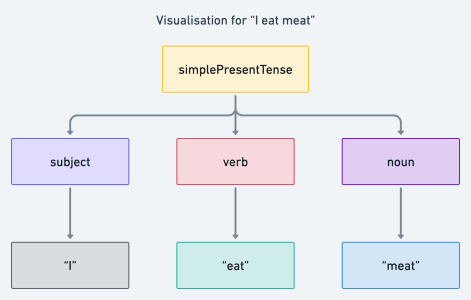
Let’s consider simple present tenses in English. For example, intuitively, we may know that “I read” is a valid statement while “read I” is not. To be methodical about it, we can define a context-free grammar, using the head := body format, for simple present tenses like so:
simplePresentTense := subject verb (noun)+
subject := "I" | "He"
verb := ("read" | "eat" | "go") (s | es)+
noun := "books" | meat
Based on our introduction, we can immediately tell that simplePresentTense, subject, verb, and noun are rule heads (or rule names); this also means that they are non-terminals because rules exist which can convert them to other symbols. So, for clarity, terminal symbols are represented using quotation marks and non-terminal symbols are represented without them.
The grammar definition also tells us the following:
- We can generate a simplePresentTense by combining a subject, a verb and zero or one noun
- We can replace the subject non-terminal with terminals “I” or “He”
- We can replace the verb non-terminal with terminals “read”,“sleep” or “go”
- Also, we can combine each of these terminals with “s” or “es” where appropriate, meaning we can also generate “reads”, “sleeps”, or “goes”
- We can replace the noun non-terminal with terminals “books” or “meat”
We can make some valid statements such as “He reads books” and “I eat meat” with this understanding. However, statements such as “books read he” and “I meat eat” are invalid because they don’t follow the grammar’s order. So, apart from a grammar telling us what terminals - English words, in this case - are valid, they also tell us how we must order them.
In explanck, a terminal is always a scanner-generated token (i.e. a number or an operator). And a non-terminal is a rule name that describes how we can order one or more numbers and operators to form a valid expression. With this in mind, let’s say we defined a grammar for explanck like so
expression := literal | binary | grouping
literal := NUMBER
grouping := "(" expression ")"
binary := expression operator expression
operator := "+" | "-" | "/" | " * " | "^"
We’ve learned how to interpret grammars from the simple present tense example, so what does this grammar above tell us?
- When we get an expression in explanck, it is either a literal, binary or grouping expression
- A literal expression is a number (i.e. any valid number in math). E.g. 1, 30, and 56.34
- A grouping expression is an expression wrapped in parentheses. E.g. (2 + 3), where 2 + 3 is the expression
- A binary expression is of the form left_operand operator right_operand. E.g. 2 + 3, where 2 is the left operand, + is the operator, and 3 is the right operand
- The operator in a binary expression can be one of +, -, /, * and ^
One last thing. If you look closely at explanck’s grammar, you’ll notice a recursive quality: the grouping and *
binary* rules reference the *expression* rule, and the *expression* rule references them. This cyclic relationship makes
it possible for this grammar to handle math expressions with an arbitrary nesting level like (45 * 5) - 2 * 1. Here’s
a visual representation:

Grand! Our grammar looks sufficient to handle our needs on explanck. But that’s the thing with looks: they can deceive.
The Threat of Ambiguous Grammars 🔗
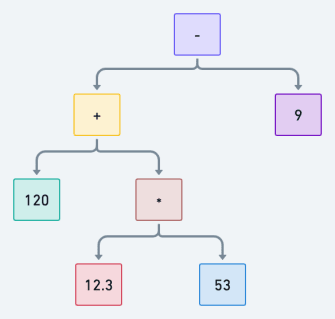
I mentioned in the [first section] that ambiguous grammars make generating more than one AST possible. With the current grammar definition for explanck, can we generate more than one AST for a given math expression? Let’s test with our example from the last post: 120 + 12.3 * 53 - 9.
Without trying too hard, I notice we can generate the following as valid ASTs from our current grammar - we use [] to highlight the order of executions for clarity:
[120 + 12.3] * [53 - 9] = 5821.2

120 + [12.3 * [53 - 9]] = 661.2

120 + [12.3 * 53] - 9 = 762.9
[[120 + 12.3] * 53] - 9 = 7002.9
If you’re interested, drawing the ASTs for the last two interpretations above is an excellent exercise.
Our examples show that ambiguity in explanck’s grammar makes operator precedence unclear. In its current state, we can resolve addition before multiplication, which can significantly change the result of an expression. However, to make a reliable evaluator, precedence must be clear, so let’s enforce that.
To enforce precedence, we must first define it. We do that in the table below, going from lowest to highest.
| Name | Explanation | Example(s) |
|---|---|---|
| expression | any type of expression | 7 * 3 - (4 + 2 ^ 3) |
| term | expressions with + or - | 4 + 2 or 4 - 2 |
| factor | expressions with * or / | 7 * 3 or 7 / 3 |
| power | expressions with ^ | 2 ^ 3 |
| primary | literal or grouping expressions | 4 or (4 + 2 ^ 3) |
Given these categorizations, we can now modify our grammar to this:
expression -> term
term -> factor (("+" | "-") factor)*
factor -> power ((" * " | "/") power)*
power -> primary ("^" primary)*
primary -> NUMBER | "(" expression ")"
Note: * means zero or more
The first thing we’ve done is break down our old binary rule into different rules that uniquely represent the expressions we’ve identified in the table above.
The second thing we’ve done is to specify precedence in our grammar. We ensure that each rule will only match expressions at their precedence level or higher. If we try to generate an AST for 120 + 12.3 * 53 - 9 again, we will find that we can only generate one of the variations - (120 + (12.3 * 53)) - 9 - which is the correct one.
Don’t fret if this doesn’t make sense right now, take my word for it. We’ll dive deeper into how this works in the next post as we bring our parser to life.
We’re mostly done here, but before we go, let’s define some data structures to represent the different types of expressions for explanck. Then, we will use these data structures to generate an expression’s abstract syntax tree when we parse.
First, we define a base expression class:
abstract class Expr {}
Then define a Literal class to store the value of a NUMBER expression, a Grouping class for expressions surrounded
by parentheses, and a Binary class for expressions with two operands and an operator. All these classes extend Expr:
// For Term, Factor & Power expression
class Binary extends Expr {
final Expr left;
final Token operator;
final Expr right;
}
// To store literal value for NUMBER
class Literal extends Expr {
final Object value;
}
// To store expression within a () pair
class Grouping extends Expr {
final Expr expression;
}
One last note: Polymorphism tells us that Binary, Literal, Grouping objects are also Expr objects. We’ll
capitalize on this later.
Thanks for sticking this out; I hope you learned something. Check out the code for the expression classes on GitHub. In the next post, we will implement a parser!